

Dependency Parsing in Computational Linguistics
Quy Huynh Phu Pham, Faculty of Foreign Languages, Ton Duc Thang University, Ho Chi Minh City, Vietnam; School of Foreign Languages and Cultures, The University of Queensland, Brisbane, Australia
Chi Cuong Chau, Faculty of Education, University of Macau, Macau SAR, China
Duong Nguyen, English Department, Iowa State University, Ames, Iowa, USA
Computational linguistics is an area of linguistics that employs computational methods to model, analyse, and process human language. Within this field, dependency parsing is one of the most widely used techniques across multiple language processing tasks, including collocation extraction, sentiment analysis, and entity recognition. In this article, we begin with a concise definition of dependency parsing, then examine its strengths and weaknesses through practical examples, and conclude with a discussion of key considerations when applying this technique.
Definition
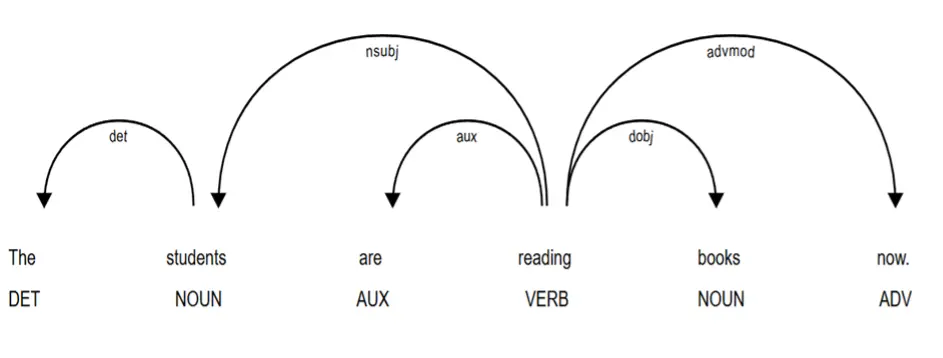
Dependency parsing is a widely used computational technique for identifying grammatical relationships between individual words in a natural language sentence. This technique is grounded in dependency grammar, which assumes binary and asymmetrical relationships between the elements of sentence structure (Tesnière, 1959; see also Osborne, 2019). Specifically, in each word pair, one word acts as a syntactically subordinate element, the dependent, and the other as the head, upon which the dependent relies (Kübler et al., 2009). There is also a root word that serves as the central element of the sentence and does not depend on any other word. Figure 1 illustrates these dependency relationships within the sentence—The students are reading books now. In the pair the students, the is a dependent modifying the head students, and in are reading, reading is the head of are. The root word is reading, which governs multiple dependents, indicated by the arrows, including are, students, and books. Syntactic roles, such as nominal subject and direct object, and grammatical elements, including noun, verb, and auxiliary, are also presented. Building on this structural framework, the following section explores how dependency parsing is used in practice across real-world language processing applications.
Figure 1
An Example of a Dependency Structure
Applications of Dependency Parsing
In this section, we focus on three specific applications of dependency parsing, including collocation extraction, sentiment analysis, and entity recognition. Each application is illustrated with specific examples to highlight the strengths of this technique.
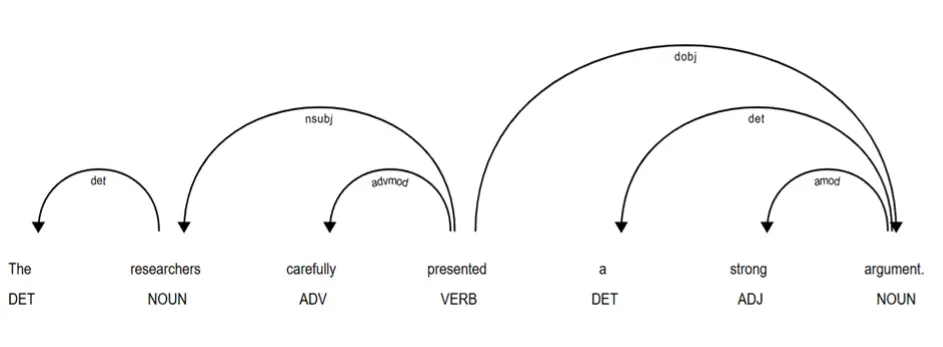
Within the field of learner corpus research, dependency parsing has been used to extract collocational pairs (e.g., Eguchi & Kyle, 2023; Paquot, 2019). For instance, Eguchi and Kyle (2023) used spaCy (Montani et al., 2023), a natural language processing (NLP) package in Python, to retrieve three types of collocations, including verb-direct object, noun-adjectival modifier, and verb-adverbial modifier, based on dependency relations in a learner corpus. To illustrate this approach, consider the dependency-parsed sentence, “The researchers carefully presented a strong argument”. As shown in Figure 2, several collocation types can be identified from the dependency relations, including carefully (adverbial modifier) + presented (verb), presented (verb) + argument (direct object), and strong (adjectival modifier) + argument (noun). A key strength of this dependency-based approach is its ability to extract linguistically meaningful collocations based on syntactic relations rather than linear word proximity. This allows for more precise identification of collocational patterns, even when words are separated within a sentence. Moreover, because dependency parsing can be applied automatically, this approach enables efficient large-scale extraction of collocations from large learner corpora.
Figure 2
An Example of Parsing Collocations
Another common application of dependency parsing is sentiment analysis (e.g., Di Caro & Grella, 2012; Li, 2016). By analysing syntactic dependencies, computers can automatically identify and classify the polarity (e.g., positive, negative, or neutral) of evaluative texts (e.g., restaurant reviews). For example, Di Caro and Grella (2012) utilized dependency parsing on a corpus of restaurant reviews to estimate sentence-level sentiment polarity by modelling how evaluative meaning is shaped by grammatical relations among words. After constructing a dependency parse tree for each sentence, they assigned initial sentiment values to words (e.g., good as positive, bad as negative, and food as neutral) and then applied linguistic rules to propagate or transform these values across dependency connections.
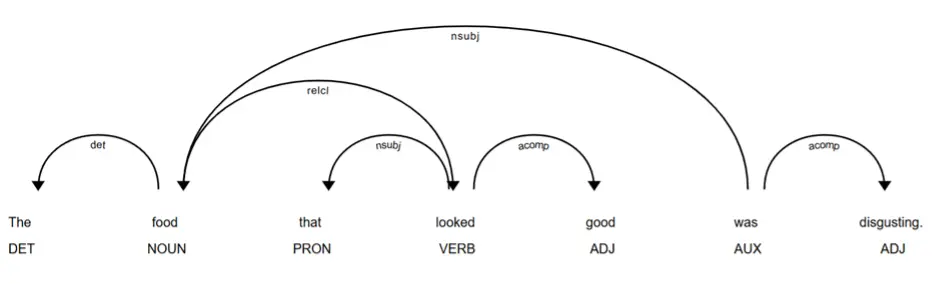
As a demonstration, consider the review “The food is good, but the service is terrible” (see Figure 3), which contains opposing opinions. However, when parsed, the computer recognizes that “good” refers to the food and “terrible” refers to the service because each adjective serves as an adjectival complement linked via a copular verb to its respective nominal subject. A more complex example is “The food that looked good was disgusting” (see Figure 4). Based on dependency relations, the overall sentiment appears to be negative because “disgusting” is the main adjectival complement of the primary verb “was”, directly modifying the subject “food”. In contrast, “good” is contained within a relative clause that modifies the subject, making it a secondary attribute rather than the sentence’s main evaluative conclusion. Overall, a dependency-based approach allows sentiment analysis to go beyond simple word counting by identifying what is being evaluated and how evaluative expressions are structured in a sentence. This leads to more accurate sentiment classification, especially in sentences that contain multiple clauses, modifiers, or conflicting sentiment cues.
Figure 3
An Example of Parsing Conflicting Reviews
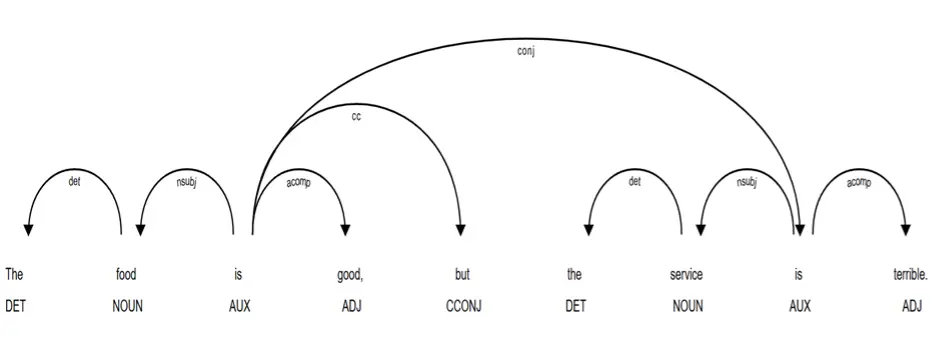
Figure 4
An Example of Parsing Multiple Clauses
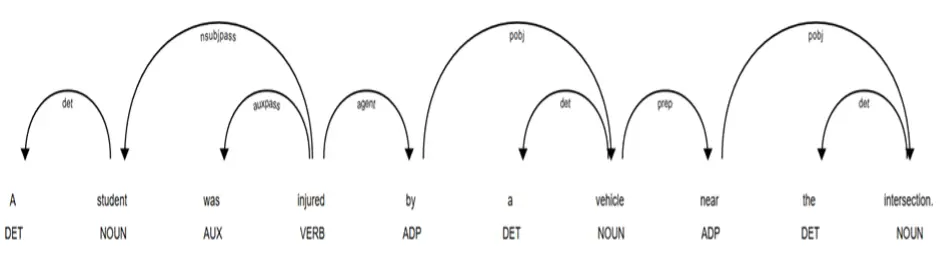
Finally, dependency parsing is a critical tool in entity relationship extraction, the process of identifying real-world entities and their connections. A recent study by Wei et al. (2025) applied this to campus traffic safety by using a parsing framework to create syntactic and semantic dependency graphs from a corpus of 236 text entries. In doing so, the model effectively captures long-distance associations between remote entities like students, motor vehicles, and intersections. As illustrated in Figure 5, in the sentence “A student was injured by a vehicle near the intersection,” the nsubjpass (nominal passive subject) tag marks student as the passive subject, showing that the student is affected by the action. The agent relation introduced by “by” links “injured” to “vehicle”, identifying the vehicle as the cause. The prep (prepositional modifier) and pobj (object of preposition) tags connect “injured” to “near the intersection”, indicating that the location modifies the injury event. In short, while entity extraction identifies the relevant entities in the sentence, incorporating dependency parsing allows those entities to be linked through their grammatical roles and relationships, clearly capturing who was involved, what happened, and where it occurred from unstructured text.
Despite its usefulness, dependency parsing presents several limitations, especially in cases of inadequate text processing and ill-formed input. The discussion below outlines these challenges in more detail.
Figure 5
An Example of Parsing Entity Relationships
Limitations of Dependency Parsing
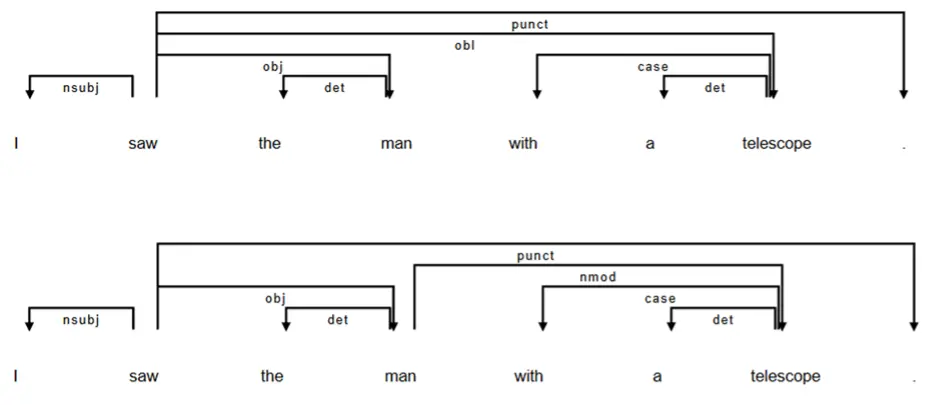
One challenge of dependency parsing is that many sentences allow more than one plausible analysis, even for human readers, and parsers may choose an analysis that does not match the intended meaning. Classic hard cases, including prepositional-phrase attachment (e.g., I saw a man with a telescope—the phrase with a telescope could describe the man or the act of seeing), coordination scope (e.g., policy and budget reforms—it is not always clear what elements are being grouped together), and long-distance dependencies (e.g., The book that the professor I met yesterday recommended was expensive—related words are separated by intervening material), can yield alternative, linguistically plausible analyses (see Figure 6). In corpus-driven research, downstream analyses often assume the parses are correct, even though parser performance is known to drop substantially when employed on imperfect inputs such as automatic speech recognition transcripts (Agmon et al., 2024; Bruno et al., 2016). In such contexts, single-dimensional metrics derived from these parses may flatten “the richness of syntactic structures” (Agmon et al., 2024, p. 555), potentially obscuring variation that is pedagogically meaningful. Thus, manual revision of dependency-annotated learner corpora is often required to ensure accurate results (see Zhang & Zhang, 2025).
Figure 6
PP-Attachment Ambiguity
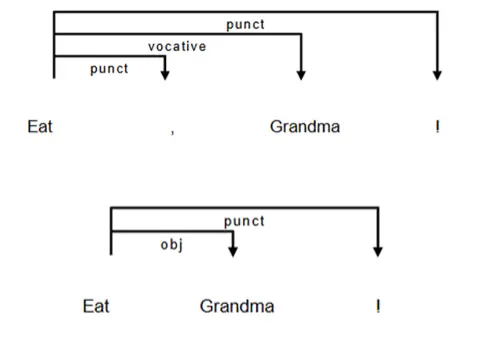
A second limitation concerns text preprocessing and punctuation. Dependency parsing serves as a later stage of the NLP pipeline and relies on accurate tokenization, lemmatization, and sentence boundary detection. Thus, missing or unconventional punctuation can introduce boundary errors that lead to distorted dependency parses (Agmon et al., 2024). In other words, many apparent parsing errors originate from earlier preprocessing steps rather than from the parser itself. Because syntactic analysis requires effective text preprocessing for the parser to accurately identify grammatical information within a sentence (Chen et al., 2018), punctuation errors can significantly affect parser performance. Figure 7 demonstrates how adding or removing a comma can change dependency structure and interpretation. With a comma, the word may be treated as a name or term used to get someone’s attention (a vocative), whereas without the comma, the same word may be treated as part of the sentence’s grammatical content, such as a noun functioning as an object. Failure to account for punctuation-related errors may ultimately lead to misleading research outcomes.
Figure 7
Punctuation Sensitivity in Dependency Parsing
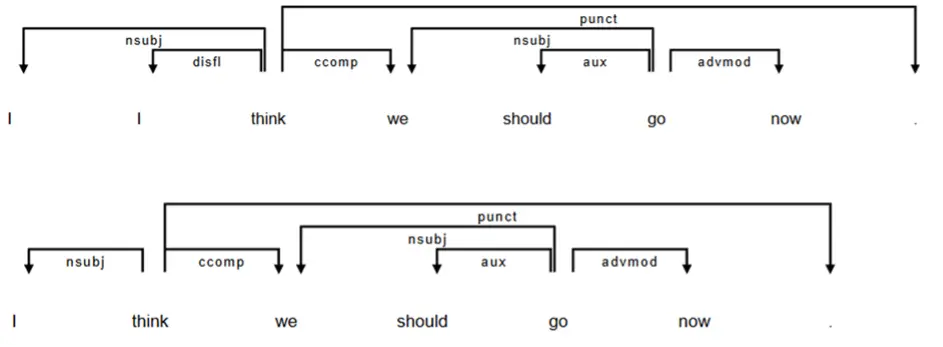
Finally, dependency parsing performance degrades when applied to non-canonical or ill-formed input, particularly in spoken transcripts and learner language. Disfluencies, including filled pauses (e.g., um, uh), repetitions (e.g., I I I think), and self-repairs (e.g., He go—he went out yesterday), violate the well-formedness assumptions present in many training corpora, yielding degraded attachment accuracy and unstable dependency graphs. Figure 8 juxtaposes a disfluent utterance and a cleaned version to show how repeated tokens introduce spurious relations. However, cleaning should be used cautiously because removing disfluencies can also remove meaningful evidence of planning, monitoring, and interaction, thereby changing what is being measured (Baker & Love, 2023; Buxó-Lugo & Slevc, 2024). For practitioners, the key is to report clearly what was cleaned and why, and to interpret parsing-based results as indicators that need contextual checking rather than as definitive proof of learners’ syntactic ability.
Figure 8
Parsing Disfluencies
We have so far provided a brief overview of dependency parsing, a powerful NLP technique for identifying grammatical relationships between words, and discussed its strengths and limitations across a range of language processing tasks. The following section focuses on key considerations for its practical applications.
Key Considerations in Dependency Parsing
In current practice, dependency parsing can be conducted using several widely adopted tools and NLP packages, including the Stanford Parser (Chen & Manning, 2014), spaCy in Python (Montani et al., 2023), and Udpipe in R (Wijffels & Straka, 2025). However, the effective application of these tools requires careful consideration of several methodological factors. The first concerns the training data of the parser. For example, spaCy is largely trained on the OntoNotes 5 corpus (Weischedel et al., 2013), which primarily consists of text produced by native speakers or highly proficient writers. As a result, applying these parsers to learner language, which often contains grammatical errors and non-standard constructions, can be challenging. In such cases, it would be helpful to first evaluate parser performance on a representative sample to identify systematic parsing errors before conducting a full analysis. A clear understanding of the training data underlying a parser is essential for its appropriate use.
The second consideration relates to the model types offered by the parser. spaCy, for instance, provides different models that vary in size and capability. Lightweight models prioritize speed and low memory usage, making them suitable for basic linguistic tasks, though with limited semantic representation. More advanced models incorporate pretrained word vectors, improving accuracy for tasks such as named entity recognition. Finally, although transformer-based models can extract rich contextual information, they often require substantially greater computational resources. Model selection, therefore, should align with specific research objectives to balance efficiency and accuracy.
In conclusion, dependency parsing has been a widely used technique in computational linguistics for identifying grammatical relationships. Because of its strengths, it has been used for a wide range of NLP tasks, including collocation extraction, sentiment analysis, and entity recognition. We hope this discussion offers useful guidance for researchers and practitioners seeking to apply dependency parsing in their own work. As NLP continues to evolve, future advances in dependency parsing will definitely further deepen our understanding of how machines process, analyse, and model human language.

Quy Huynh Phu Pham is a lecturer at the Faculty of Foreign Languages, Ton Duc Thang University, Ho Chi Minh City, Vietnam. He is currently pursuing a PhD at the University of Queensland and serves as an editorial assistant for System. He holds an MA in TESOL from Michigan State University, with research interests in learner corpus linguistics, computational linguistics, and data-driven learning.

Chi Cuong Chau is a visiting lecturer at Ho Chi Minh City University of Education and an English Language Education MPhil student at the University of Macau. He holds an MA in TESOL from Nottingham Trent University. His research focuses on informal language learning, extensive reading, collocations, and corpus-informed pedagogy.

Duong Nguyen is a Ph.D. student in the Applied Linguistics and Technology program at Iowa State University. She holds a Master’s degree in TESOL from Michigan State University. As an English teacher, she aspires to integrate innovative teaching methods into language classrooms. As a researcher, she draws on her classroom experience to motivate studies that support effective language learning and teaching. Her main research interests include corpus linguistics, language assessment, and the intersection of these two areas.
References
Agmon, G., Pradhan, S., Ash, S., Nevler, N., Liberman, M., Grossman, M., & Cho, S. (2024). Automated measures of syntactic complexity in natural speech production: Older and younger adults as a case study. Journal of Speech, Language, and Hearing Research, 67(2), 545–561. https://doi.org/10.1044/2023_JSLHR-23-00009
Baker, C., & Love, T. (2023). Modulating complex sentence processing in aphasia through attention and semantic networks. Journal of Speech, Language, and Hearing Research, 66(12), 5011–5035. https://doi.org/10.1044/2023_JSLHR-23-00298
Bruno, J. V., Cahill, A., & Gyawali, B. (2016). A protocol for annotating parser differences. ETS Research Report Series, 2016(1), 1–12. https://doi.org/10.1002/ets2.12086
Buxó-Lugo, A., & Slevc, L. R. (2024). Integration of input and expectations influences syntactic parses, not just sentence interpretation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 50(3), 500–508. https://doi.org/10.1037/xlm0001230
Chen, D., & Manning, C. (2014). A fast and accurate dependency parser using neural networks. In A. Moschitti, B. Pang & W. Daelemans (Eds.), Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 740–750). Association for Computational Linguistics. https://doi.org/10.3115/v1/D14-1082
Chen, X., Li, H., & Gui, M. (2018). Instructional effects of syntactic parsing on Chinese college students’ EFL reading rates. Journal of Education and Training Studies, 6(11), 176–185. https://doi.org/10.11114/jets.v6i11.3470
Di Caro, L., & Grella, M. (2013). Sentiment analysis via dependency parsing. Computer Standards & Interfaces, 35(5), 442–453. https://doi.org/10.1016/j.csi.2012.10.005
Eguchi, M., & Kyle, K. (2023). L2 collocation profiles and their relationship with vocabulary proficiency: A learner corpus approach. Journal of Second Language Writing, 60, Article 100975. https://doi.org/10.1016/j.jslw.2023.100975
Kübler, S., McDonald, R., & Nivre, J. (2009). Dependency parsing. Springer. https://doi.org/10.1007/978-3-031-02131-2
Li, L. (2016). Identification of informative reviews enhanced by dependency parsing and sentiment analysis. In IEEE Press (Ed.), 2016 First IEEE International Conference on Computer Communication and the Internet (ICCCI) (pp. 476–479). IEEE Press. https://doi.org/10.1109/CCI.2016.7778968
Montani, I., Honnibal, M., Boyd, A., Van Landeghem, S., & Peters, H. (2023). explosion/spaCy: v3.7.2: Fixes for APIs and requirements (Version 3.7.2) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.10009823
Osborne, T. (2019). A dependency grammar of English: An introduction and beyond. John Benjamins Publishing Company. https://doi.org/10.1075/z.224
Paquot, M. (2019). The phraseological dimension in interlanguage complexity research. Second Language Research, 35(1), 121–146. https://doi.org/10.1177/0267658317694221
Tesnière, L. (1959). Eléments de Syntaxe Structurale. Klincksieck.
Wei, F., Liu, X., Pan, L., Zhao, W., Shi, G., Zeng, Z., & Jiao, Y. (2025). Entity relationship extraction method based on dependency parsing and graph neural networks. Scientific Reports, 16, Article 3827. https://doi.org/10.1038/s41598-025-33922-7
Weischedel, R., Palmer, M., Marcus, M., Hovy, E., Pradhan, S., Ramshaw, L., Xue, N., Taylor, A., Kaufman, J., Franchini, M., El-Bachouti, M., Belvin, R., & Houston, A. (2013). OntoNotes release 5.0. Linguistic Data Consortium. https://doi.org/10.35111/xmhb-2b84
Wijffels, J., & Straka, M. (2025). udpipe: R package for tokenization, parts of speech tagging, lemmatization and dependency parsing based on the UDPipe natural language processing toolkit (Version 0.8.15) [Computer software]. Github. https://github.com/bnosac/udpipe
Zhang, Y., & Zhang, L. J. (2025). Use of dependency-annotated learner corpora in measuring syntactic complexity for granularity, accuracy, consistency, and transparency: Implications for research and teaching. TESOL Quarterly, 59(2), 1050–1063. https://doi.org/10.1002/tesq.3370