

Embracing Codemeshing in Language Teaching: A Corpus-Based Approach to Writing Pedagogy
Malila Prado, BNU-HKBU United International College, Zhuhai, China
Corpus linguistics (CL) is a branch of applied linguistics that utilizes large banks of machine-readable texts. Armed with online, do-it-yourself, or learner corpora, teachers may foster students’ research and language skills (e.g., Silvana Dushku’s article in the February 2023 issue of ALIS Newsletter). Among a vast array of possibilities, one of the most striking is its potential to allow students to explore and investigate language themselves. Rather than bringing to class textbooks designed based on intuition or idealized speakers, by using corpora teachers may present real language use for students to explore and analyze how certain linguistic choices are shaped by the settings in which they are produced (Friginal, 2018). This is also an alternative to presenting dominant language varieties only, which reinforces the belief that what does not fit within the realm of those idealized varieties is deficient (Canagarajah, 2012).
The use of corpus in English language classrooms continues to grow among teachers and learners when it comes to helping develop learner writing. Teachers may select a specific linguistic phenomenon and have students analyze it through a corpus that can be either available online or compiled from student productions. Teachers may then design activities based on the data so that students themselves can come up with usage rules guided by reflective questions, or ask students to search for that linguistic feature on corpora.
For the past three years, I have been teaching writing to EFL students in China. Through a corpus-based study of students’ text productions, I noticed that although they offered rich descriptions of people and places, many consisted of infrequent or old-usage words, making the texts hard to read. When the texts were analyzed in a vocabulary profiler (i.e., https://versatext.versatile.pub), they were confirmed as having high lexical density, with the tool classifying the students’ writing between B2–C1 writing level. However, a corpus investigation into their texts signaled an aspect I had initially misjudged: the students were using many words in pinyin, a phonetic written representation of Chinese, therefore a good representation of codemeshing. Codemeshing, simply defined, is the mixing of different codes, or languages in our case; however, its use is far from simple. It is dynamic, nuanced, and complex. Canagarajah (2012) discussed the importance of codemeshing in academic writing, stating that its use helps students from less privileged social groups to voice their identity, while its avoidance accords with privileged language domains.
Although Canagarajah (2012)’s book does not mention CL among his many suggestions of pedagogical practices that value what he calls translingual practices, this article aims to demonstrate that CL may assist language teachers, more particularly those interested in writing, in the same direction, by addressing codemeshing.
A Mini-Case: Chinese EFL Learners’ Engagement With Corpus in Writing Classroom
In the corpus investigation of my students’ writing productions, I noted that some of the Chinese words they were using were proper names, famous places, or other words that were easy to understand, but many presented challenges to international readers. This is one of the reasons why the vocabulary complexity was high: the tool did not recognize those words and labeled them as rare occurrences. Reminded by Canagarajah (2012) that codemeshing was a strategy that helped students enact their identity in texts, I opted to work with the findings that I retrieved from the corpus of their written productions. I gave the students part of a wordlist generated from their corpus. This part presented only infrequent words, given that those discrete words in pinyin were hardly repeated, even though the phenomenon was not. This is the opposite of mainstream work with CL, which often starts from the most frequent words. Nevertheless, infrequent words often suggest highly specific features (see Figure 1):
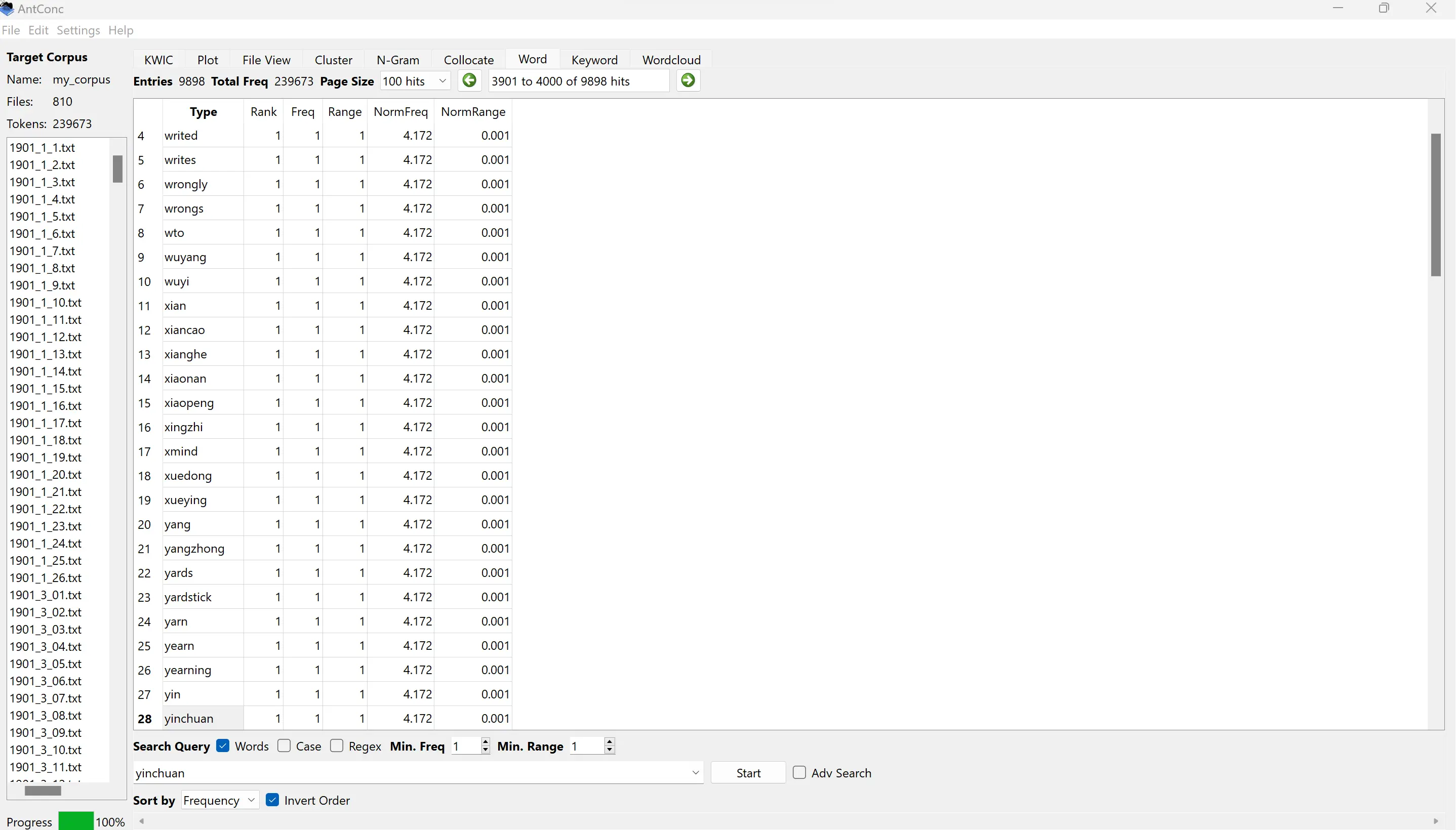
Figure 1. A Segment of an Inverted Wordlist
The wordlist in Figure 1, generated through Antconc (Anthony, 2023), contains some examples of words that appeared only once in the corpus. This can be done by clicking on the “Inverted Order” box on the bottom of the figure so that the tool can be configured to invert the frequency from least to most common. The words in Figure 1 can be simply rare in the students’ productions (such as yardstick), but many are Chinese words. I then selected a few of those words by clicking on them twice, which in Antconc retrieves concordance lines (as in Table 1):
Table 1. Concordance Lines with Examples of Words in Chinese
|
ic spots in my hometown. For example: |
zhenbeibao |
western film and Television City, Shapot |
|
s and lanes are filled with Fuding meat, |
Yangzhong |
rice noodles, Fu`an noodles, Fuan stew p |
|
m. Excitingly, some mothers dressed in |
cheongsam |
which is a symbol of victory to hope thei |
|
ying for passing the last day of a year is |
guonian |
then my hometown Wuhan has guozao |
As can be seen in Table 1, the words in the center are representations of places, foods, and people in China. These words deserved their place in the texts as they indicated that students were willing to express their own culture and knowledge in the texts. However, these words may hinder the understanding of those who do not share the same linguistic or cultural repertoire. To tackle this difficulty, a more complete wordlist with infrequent words and Table 1 were distributed to students, who were then asked to discuss in groups whether international readers unfamiliar with the culture would understand those words. Students also had to come up with strategies that would make those infrequent words understood by a larger audience. In the event, they came up with pragmatic strategies such as explicitation and paraphrasing, preserving their codemeshing while bridging local knowledge to international readers (Prakash & Kapoor, 2021). These discussions were reflected in the students’ later productions (refer to Table 2):
Table 2. Sentences With Words in Chinese Followed by Pragmatic Strategies
|
For instance, a large number of people from around the world are interested in our Chinese language, or as we call it "Pu Tong Hua.” |
|
They sell goods through Taobao, Tianmao, Jingdong and other platforms to attract consumers with the biggest discount. |
|
…they always perform Chaozhou opera, which is a unique and famous drama in the Chaoshan area. |
|
In China, there is a kind of food called "馄饨”. In contrast, there is no concept of "馄饨" in English. The word "wonton" is created by the Chinese pronunciation. |
Table 2 shows only four out of many examples found in the students’ writings after the discussions of the infrequent words. As we can see, the students creatively found ways to either explain the Chinese words or to emphasize their choices. In the first example, the student did more than simply expressing possession of their language (through the possessive pronoun our); in addition, students also felt the need to express how the name of the language is expressed in Chinese: Pu Tong Hua. In the second example, instead of employing names of international platforms, the student used Chinese names and explained the category to which those names belong. In the third example, the student paraphrased through a relative clause. The last example includes the ideogram and metalanguage, emphasizing that there is no English correspondence to the linguistic choice. These instances are more than mere language transfer; they are choices.
Concluding Remarks
When we teach our students that codemeshing is not welcome, we are not basing our decisions solely on normative grammar. Instead, we rely on narratives that promote idealized language as models, preventing our students from developing a more wholesome attitude in relation to the language they are learning to master. By presenting students with corpus findings involving their own texts, such as the wordlists and concordance lines, we give students the opportunity to reflect on their or their peers’ choices. This helps them notice uses beyond prescriptive grammar, and accept linguistic choices guided by the enactment of their agency. As corpus investigators of their own production, students may understand how their choices are respected and their use of English legitimized. By doing so, teachers may embrace students’ multilingual resources as a valid form of expression and acknowledge the richness and creativity that such resources add to students’ writing.
References
Anthony, L. (2023). Antconc (Version 4.2.4) [Computer software]. Waseda University. https://www.laurenceanthony.net/software/antconc/
Canagarajah, S. (2012). Translingual practice: Global Englishes and cosmopolitan relations. Routledge. https://doi.org/10.4324/9780203073889
Friginal, E. (2018). Corpus linguistics for English teachers: New tools, online resources, and classroom activities. Routledge. https://doi.org/10.4324/9781315649054
Prakash, O., & Kapoor, A. (2021). Code-mixing, digital media, and negotiated identity of the urban youth in India. In O. Prakash & R. Kumar (Eds.), Linguistic foundations of identity: Readings in language, literature, and contemporary cultures (pp. 304–317). Routledge.
 Malila Prado has been working with TESOL and teacher education for more than 25 years. She has employed corpus linguistics tools in her work since 2008, initially with ESP (aviation English) and, more recently, with learner corpora.
Malila Prado has been working with TESOL and teacher education for more than 25 years. She has employed corpus linguistics tools in her work since 2008, initially with ESP (aviation English) and, more recently, with learner corpora.